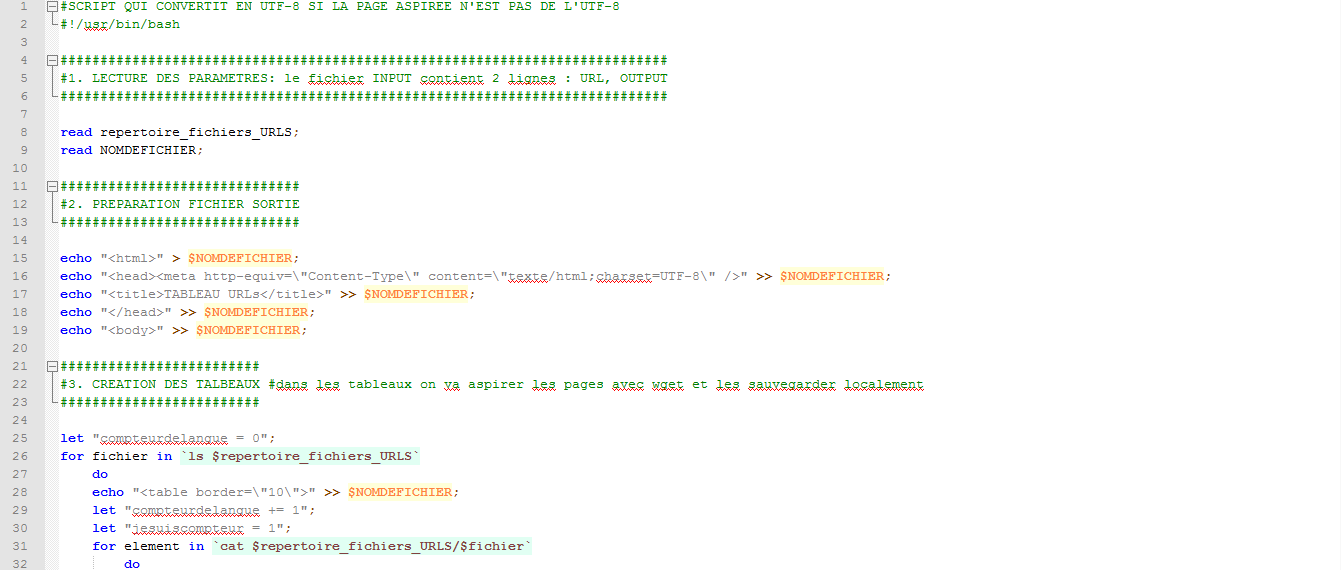
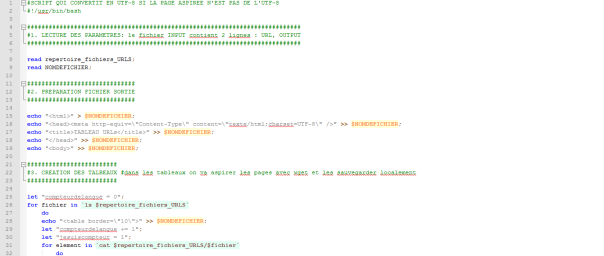
Nous continuons d’améliorer notre script afin d’exploiter au maximum les données de nos pages aspirées. Il nous faut donc désormais traiter les pages qui ne sont pas encodées en utf-8. Pour ce faire, nous allons chercher l’encodage de la page, savoir si celui-ci est connu de la commande « iconv » et le convertir en utf-8 pour pouvoir ensuite dumper cette page.
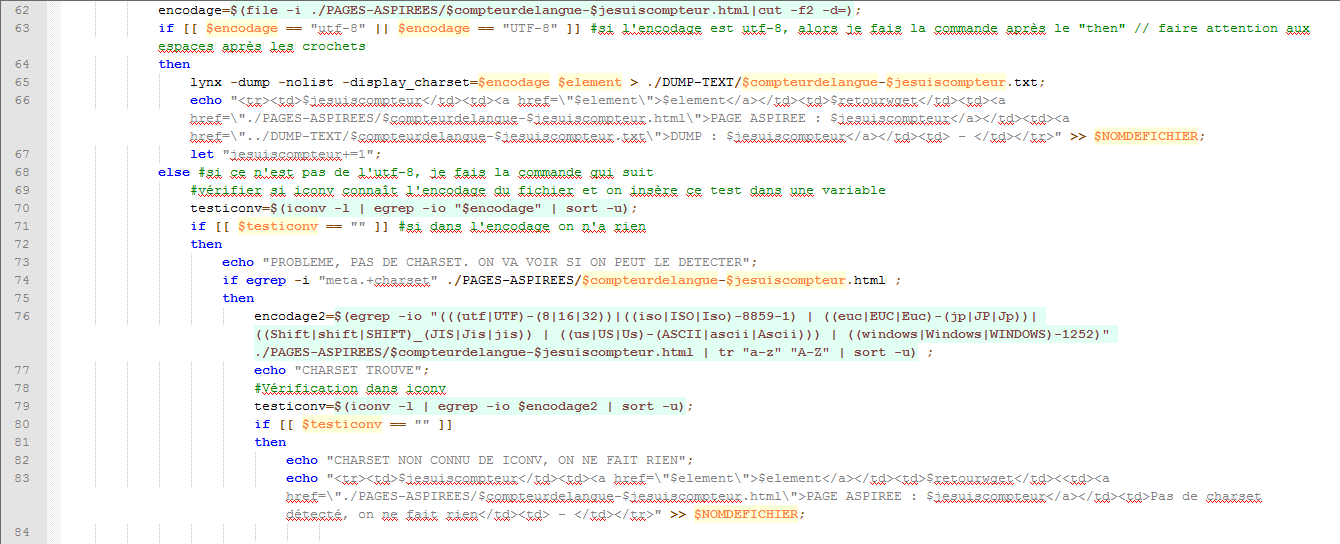
Nous utilisons la commande egrep pour trouver où est l’encodage dans la page :
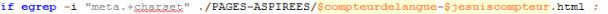
Une fois trouvé, on essaye de savoir quel est l’encodage de la page avec la commande egrep à nouveau et on l’insère dans une variable :

Ensuite, si on ne trouve pas d’encodage, on ne fait rien :

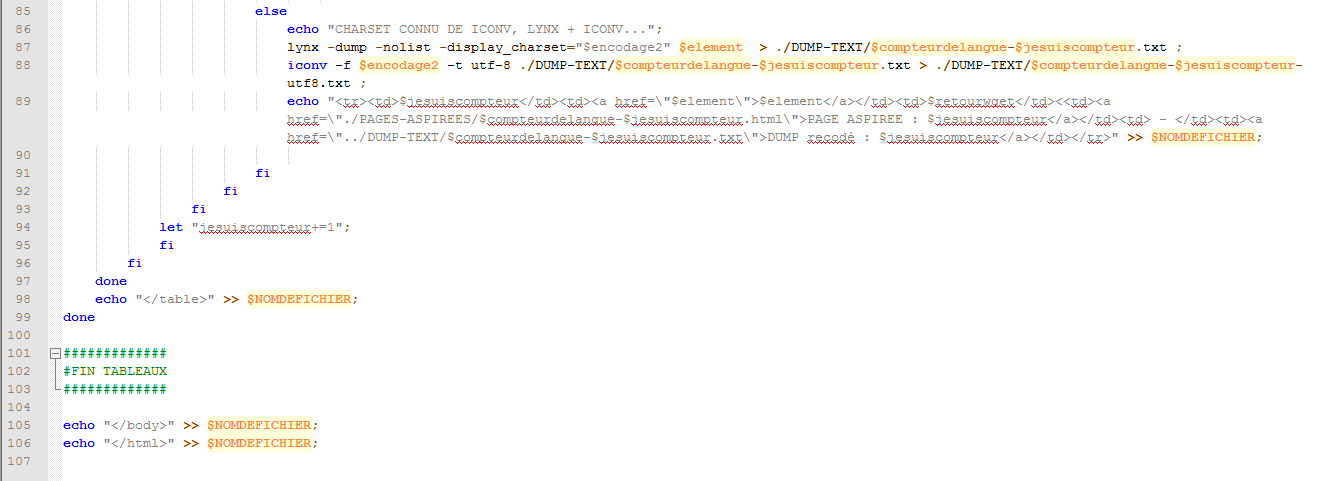
Sinon, on fait le changement d’encodage grâce à la commande iconv et on dump la page avec la commande lynx :

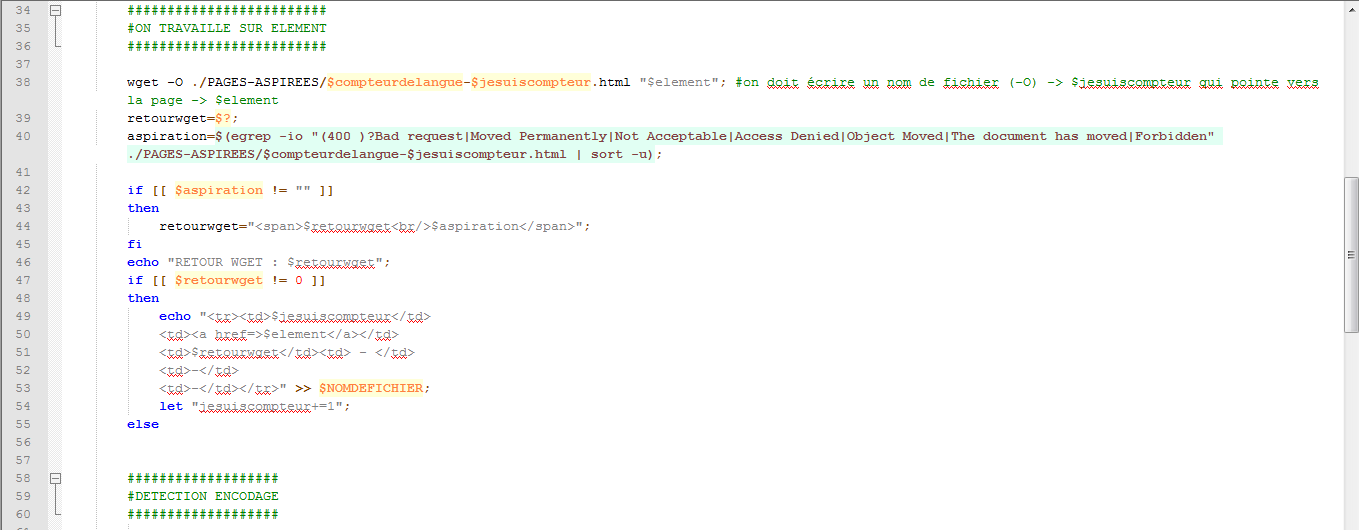
Nous avons également inséré une instruction qui permet de savoir si, dès l’aspiration de la page, il y a un problème ou non. Nous l’avons inséré dans une variable que nous avons appelée aspiration : 
Si tout se passe bien, on passe à la détection de l’encodage de la page comme nous l’avons vu dans les scripts précédents.
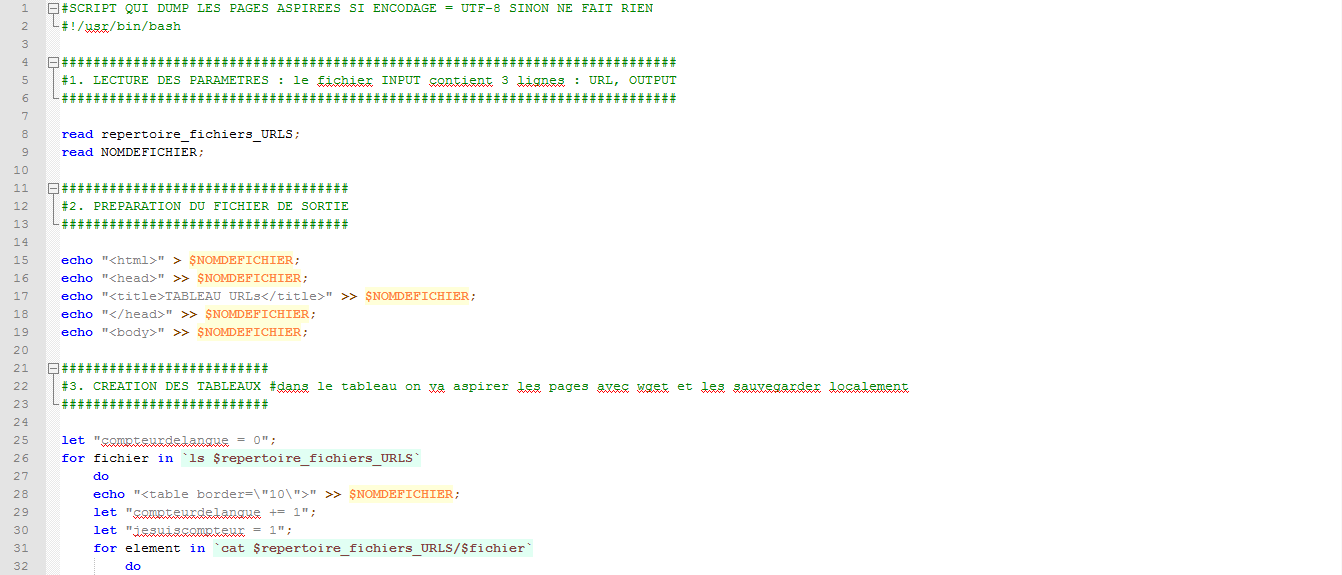
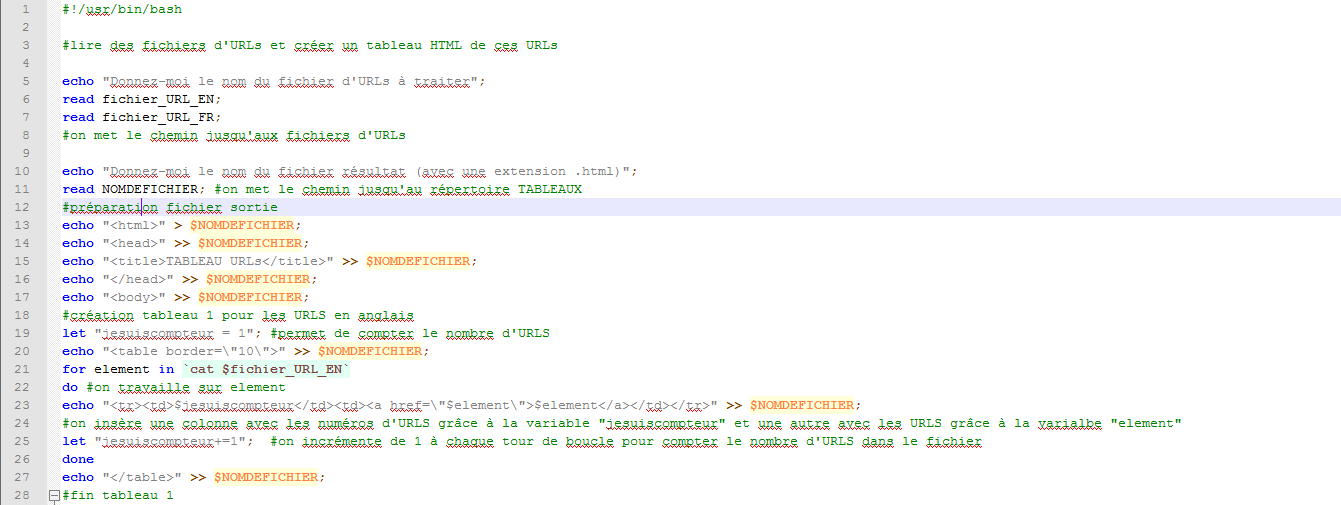
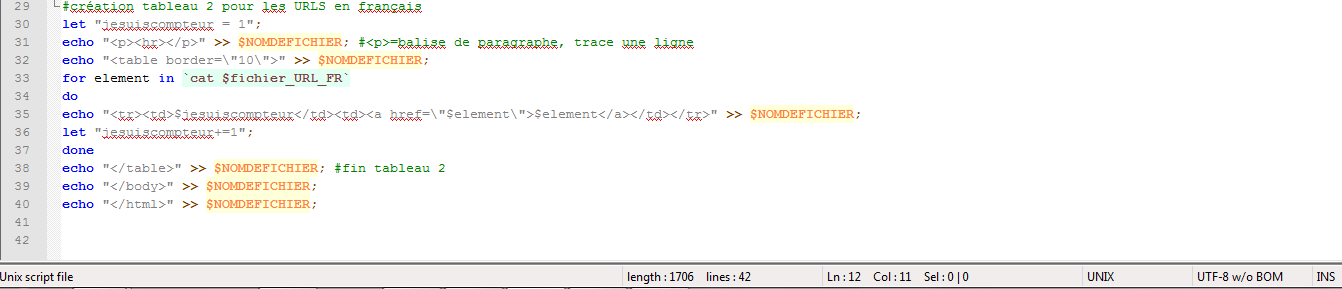
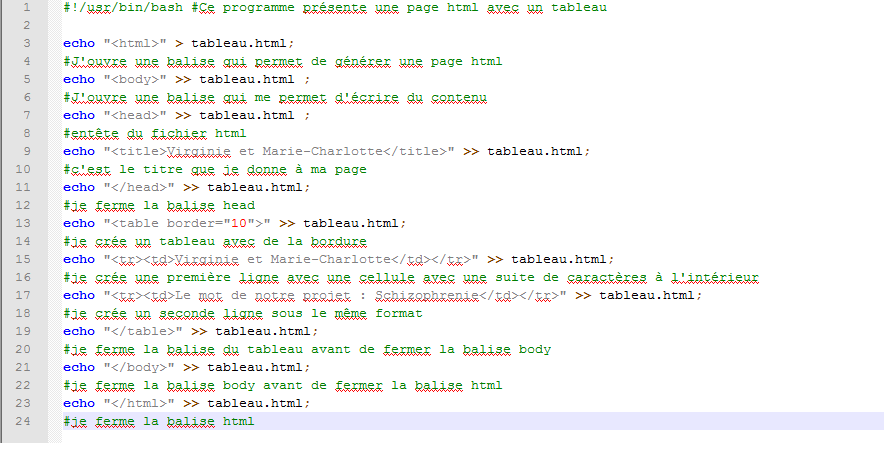
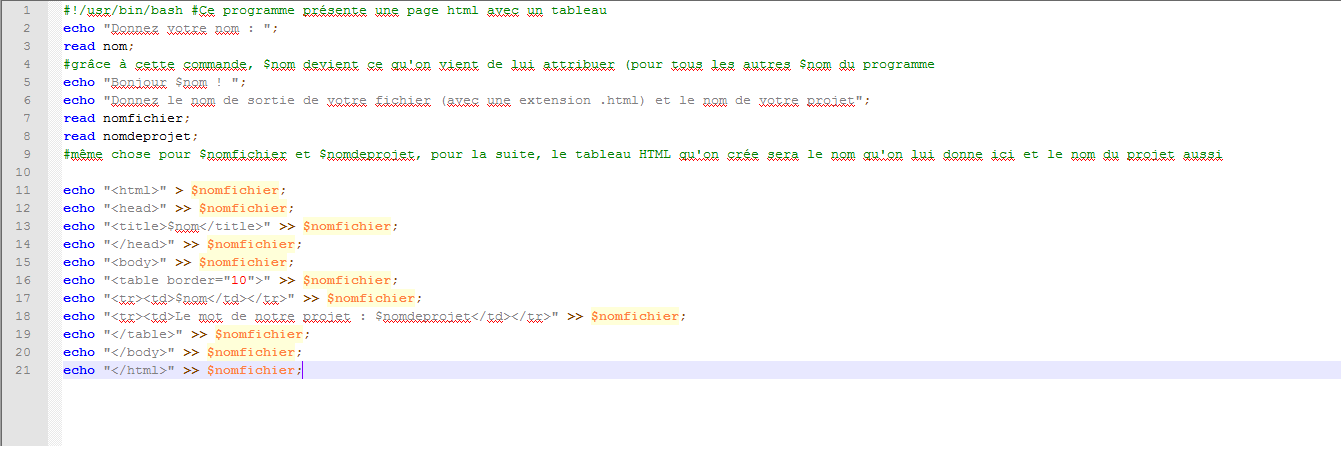
Voici maintenant l’état du script à ce stade :
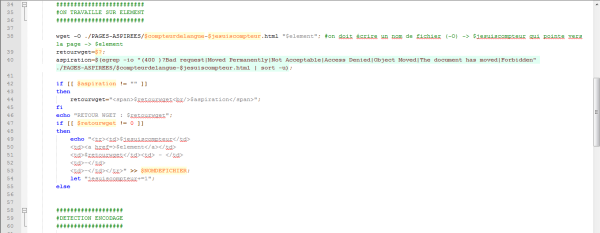
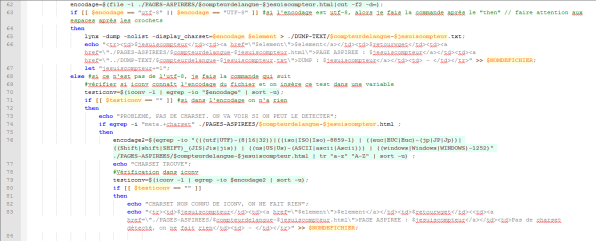
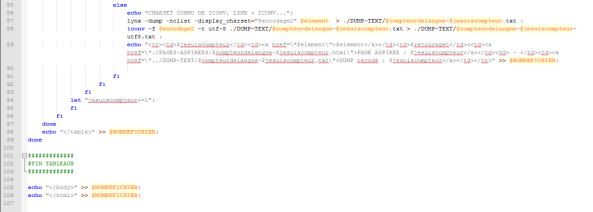
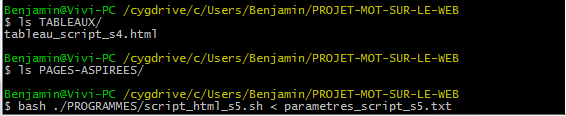
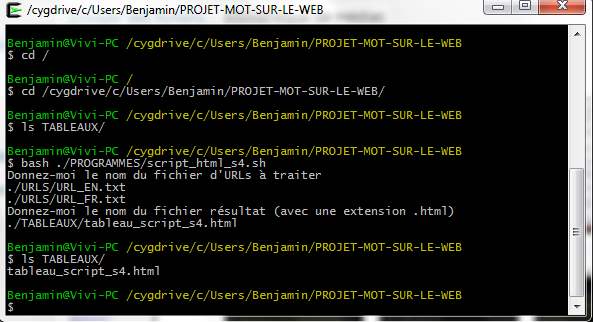
Nous lançons le script dans le terminal en vérifiant au préalable que nous nos répertoires sont vides et que le contenu du fichier paramètres correspond bien à ce que nous avons indiqué dans le script :
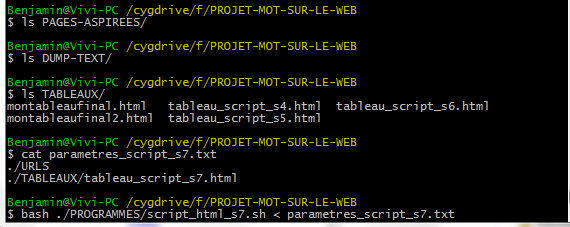
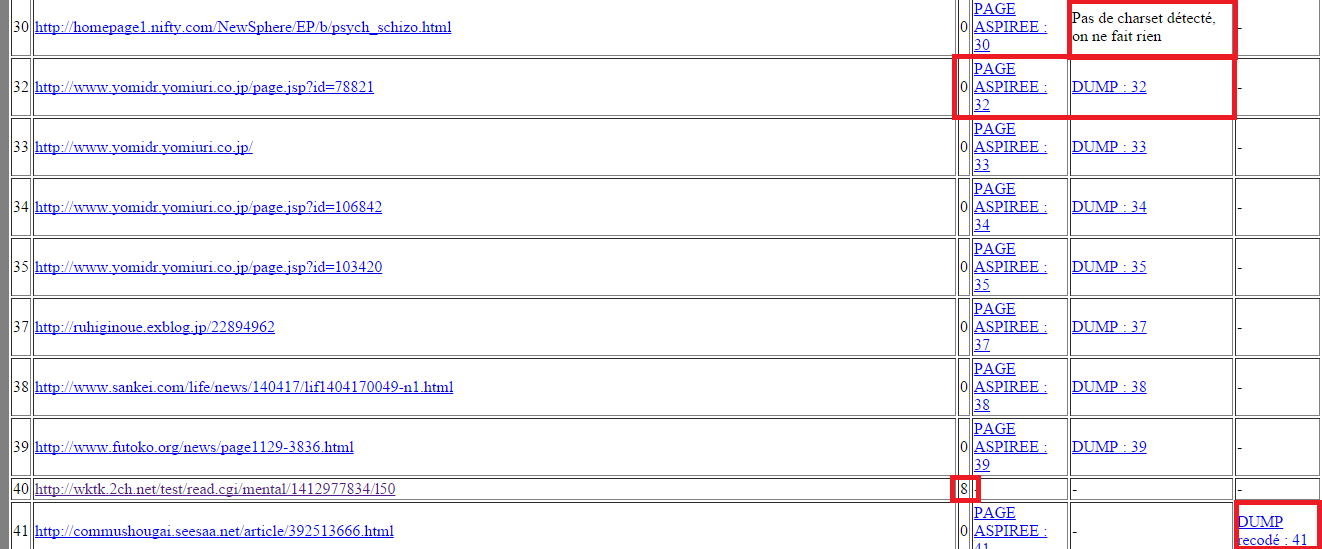
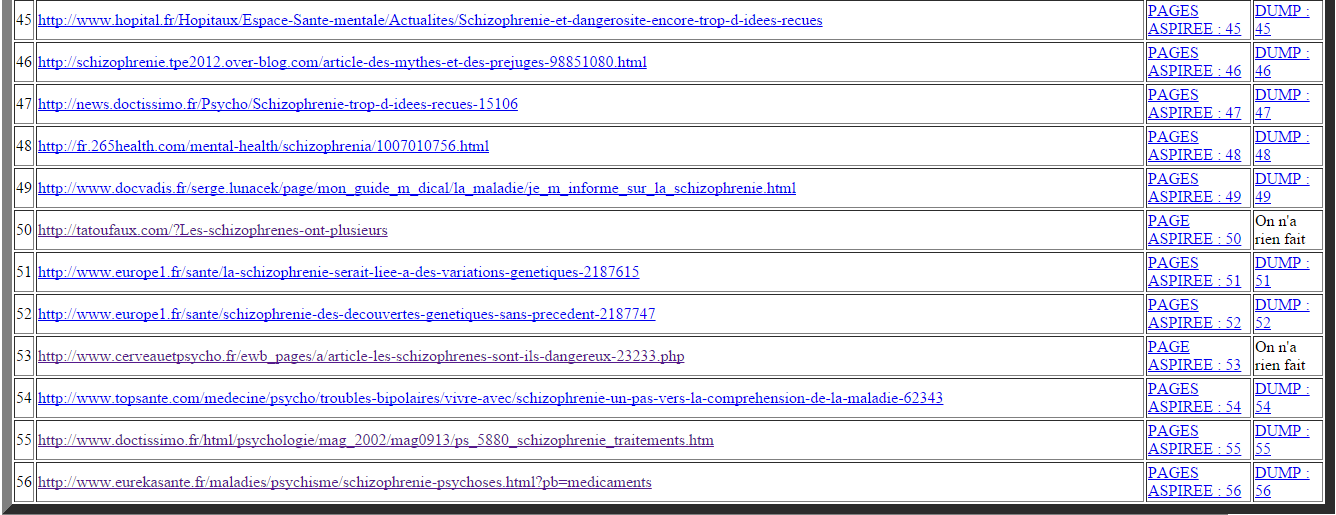
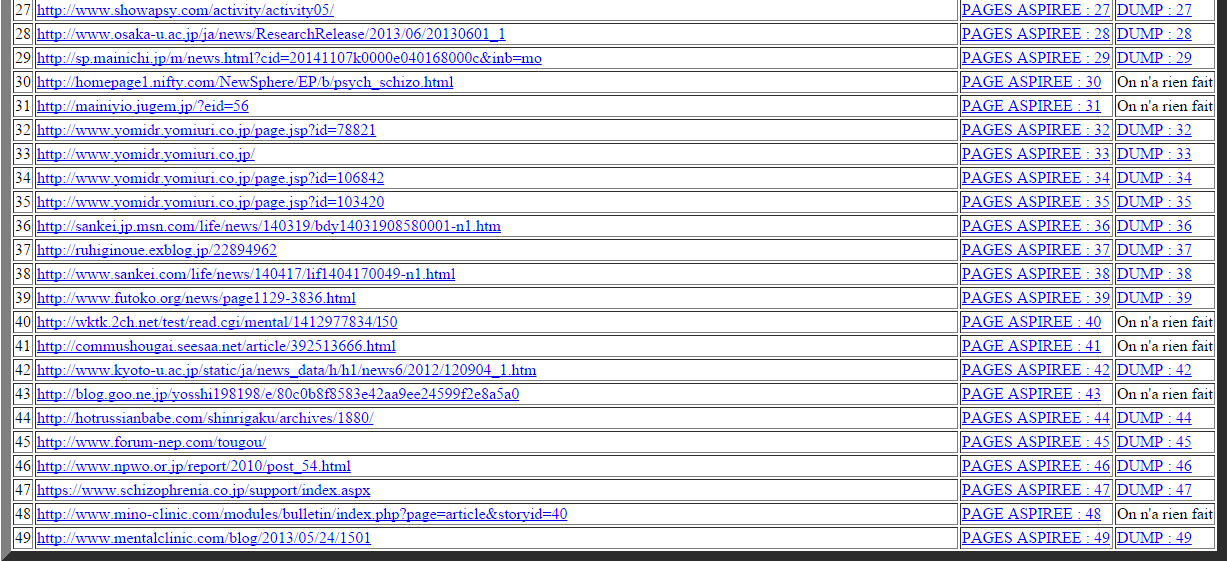
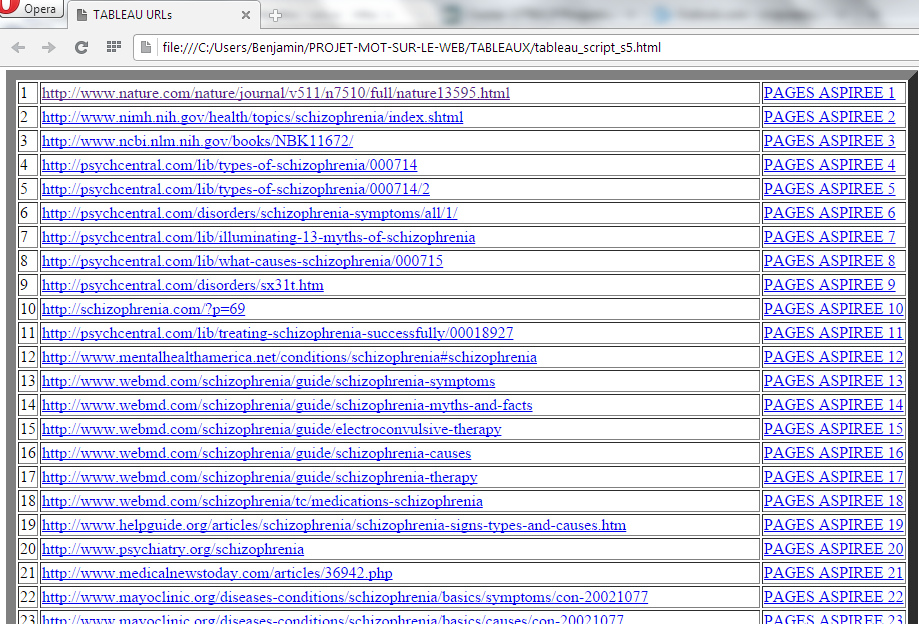
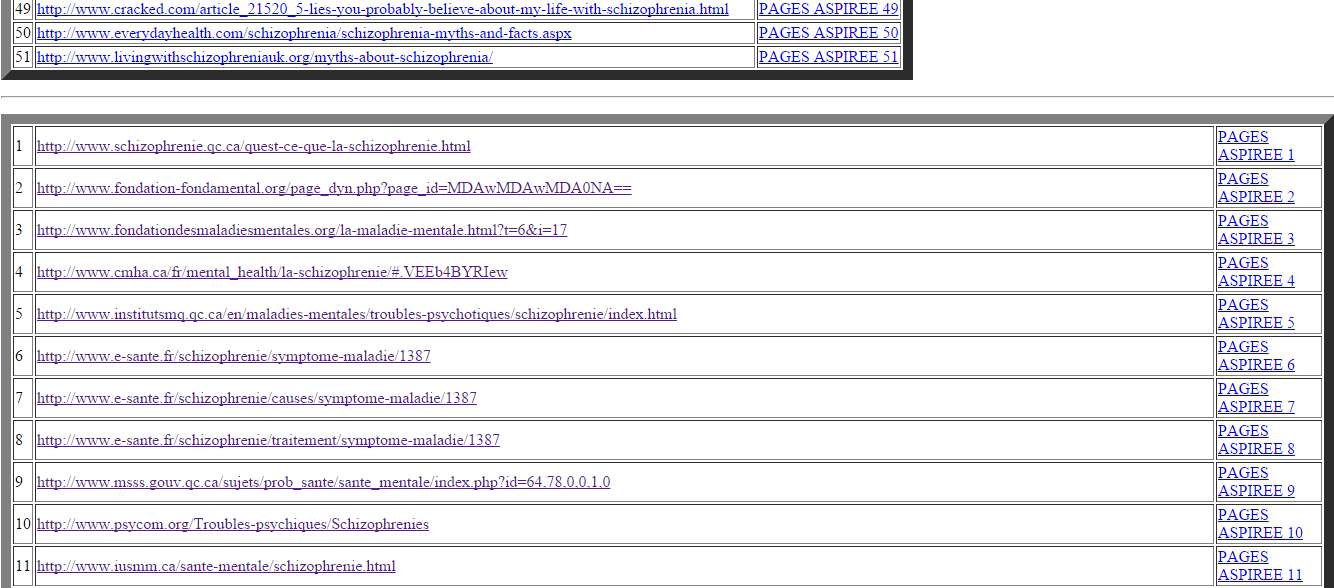
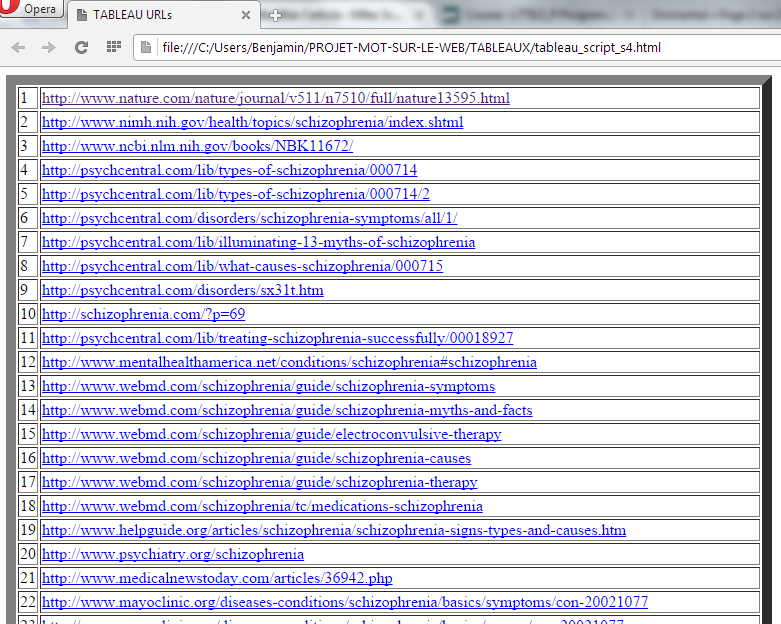
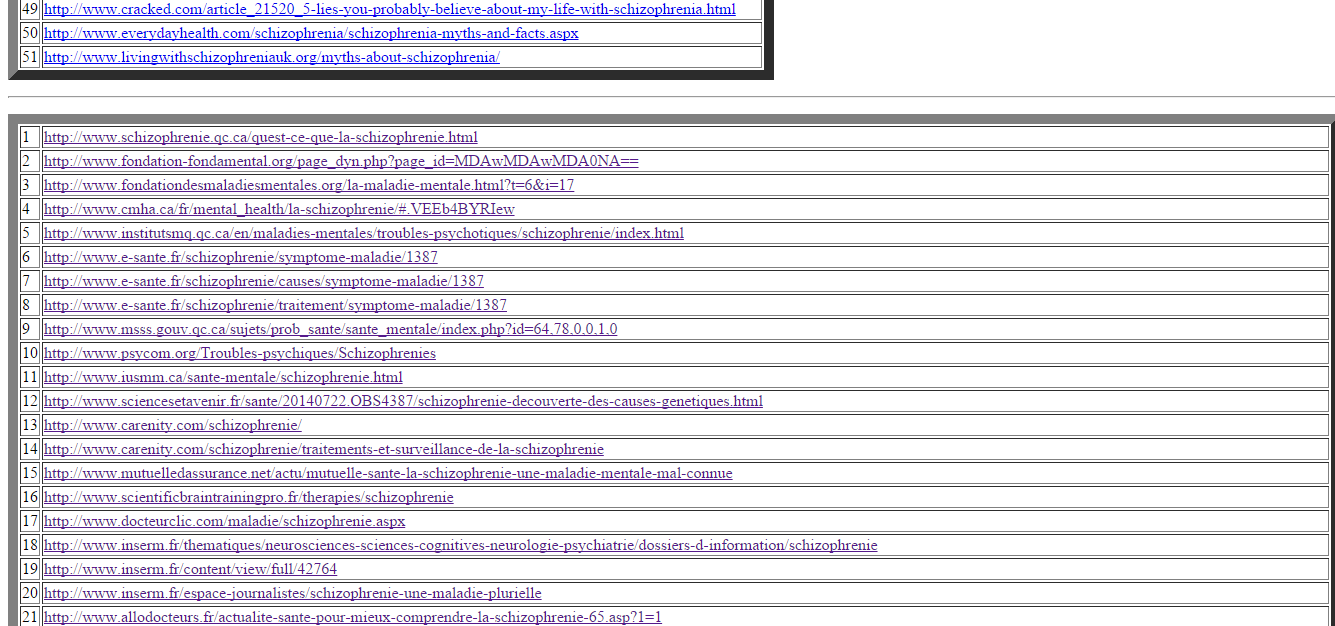
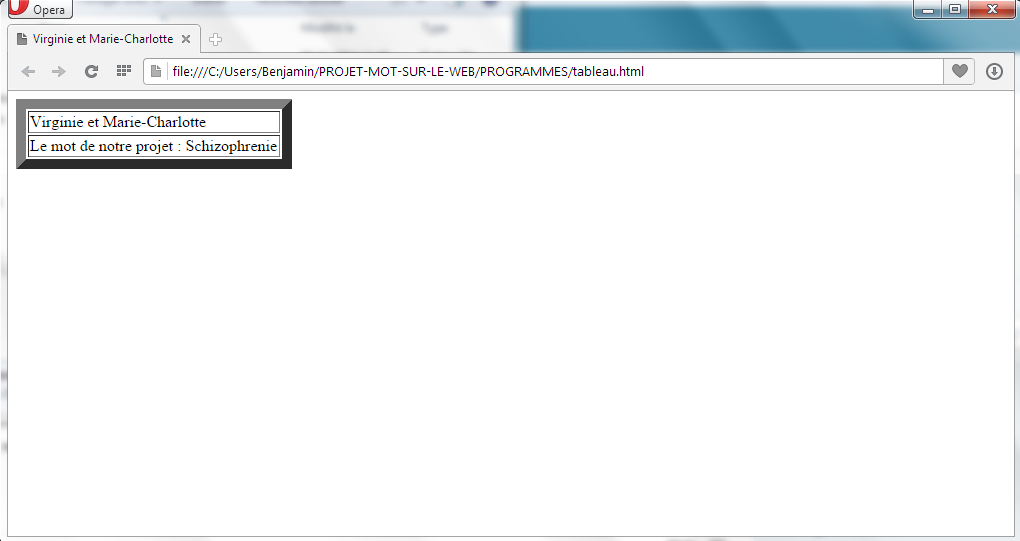
Les tableaux devenant de plus en plus grands, nous ne montrons qu’un aperçu de ce que cela donne mais on y trouve toutes les configurations possibles (c’est-à-dire, si tout se passe bien, s’il y a un problème dans l’aspiration, s’il y a un problème d’encodage et si on a changé l’encodage en utf-8).